服务器环境巡检命令
服务器环境巡检命令
步骤
1、CPU指标
1 | |
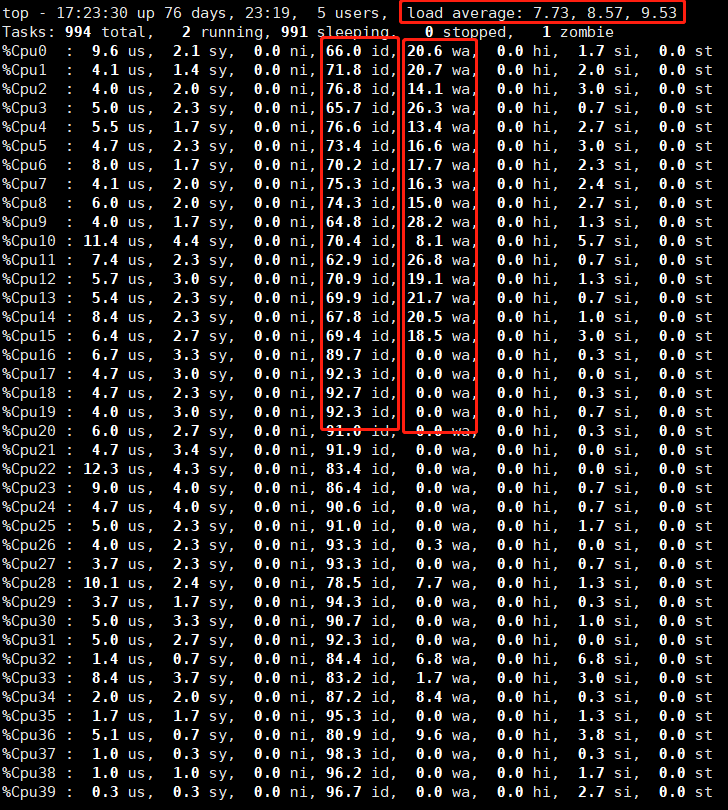
load average: 三个数字分别为最近1分钟,5分钟,15分钟的平均负载, 可认为使用的核心数量, 负载值低于CPU核心数的70%是比较正常的,超过CPU核心数的70%-100%时可能是繁忙状态,超过100%时表示系统超负荷。
id: CPU空闲时间百分比
wa: 等待I/O的时间百分比
2、内存指标
1 | |

used:表示已使用的物理内存量
3、磁盘指标
1 | |

Device:表示磁盘设备的名称。
rrqm/s:表示每秒合并的读请求次数。当操作系统在较低层次上合并相邻的读请求时,可以提高磁盘性能。
wrqm/s:表示每秒合并的写请求次数。当操作系统在较低层次上合并相邻的写请求时,可以提高磁盘性能。
r/s:表示每秒从设备读取的次数。
w/s:表示每秒向设备写入的次数。
rkB/s:表示每秒从设备读取的数据量,以KB为单位。
wkB/s:表示每秒向设备写入的数据量,以KB为单位。
avgrq-sz:表示平均每个请求的扇区数,该值越大表示每个I/O请求传输的数据量越多,有时可以用来衡量I/O请求的大小。
avgqu-sz:表示平均I/O队列长度,如果这个值较大,可能意味着磁盘I/O出现瓶颈。
await:表示I/O请求的平均等待时间,通常用来衡量磁盘的响应时间。
%util:表示设备的利用率,即设备处于繁忙状态的百分比。
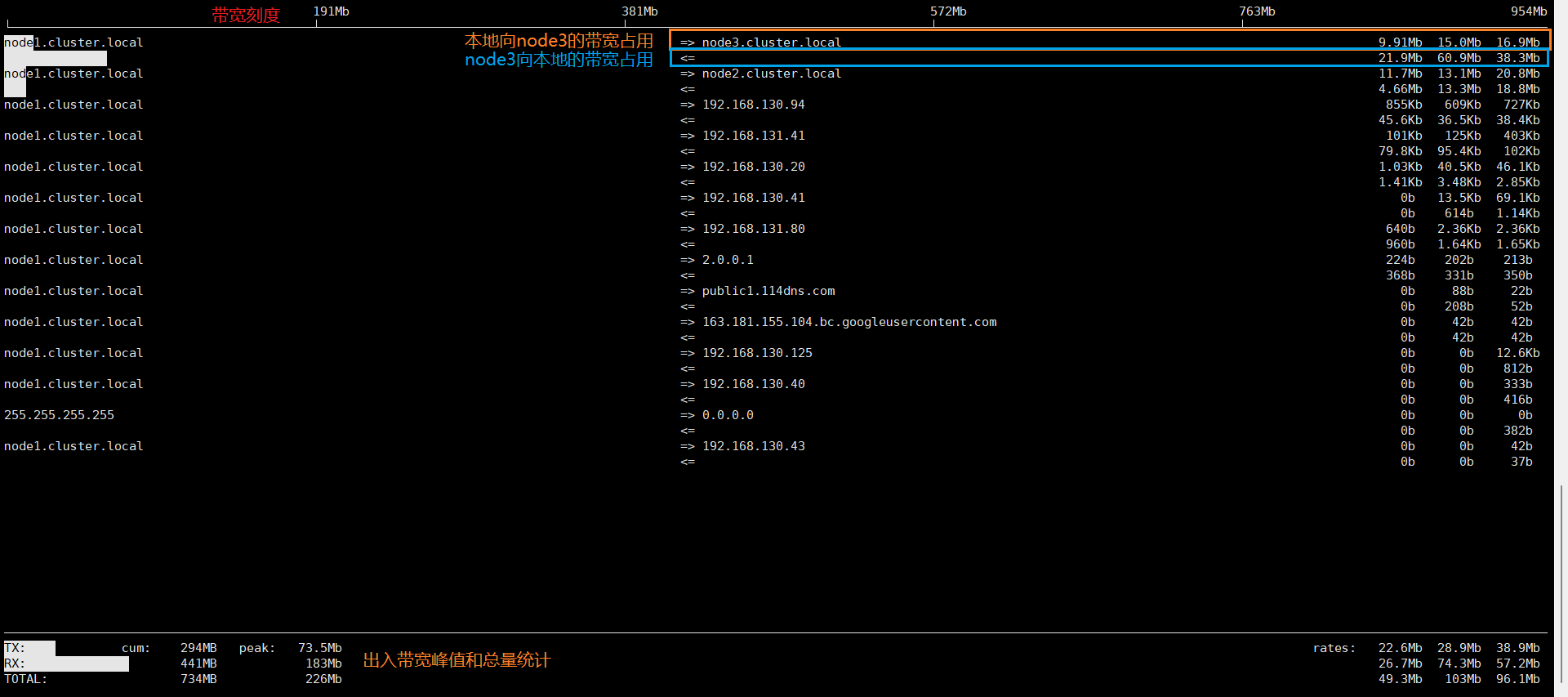
4、网络指标
1 | |
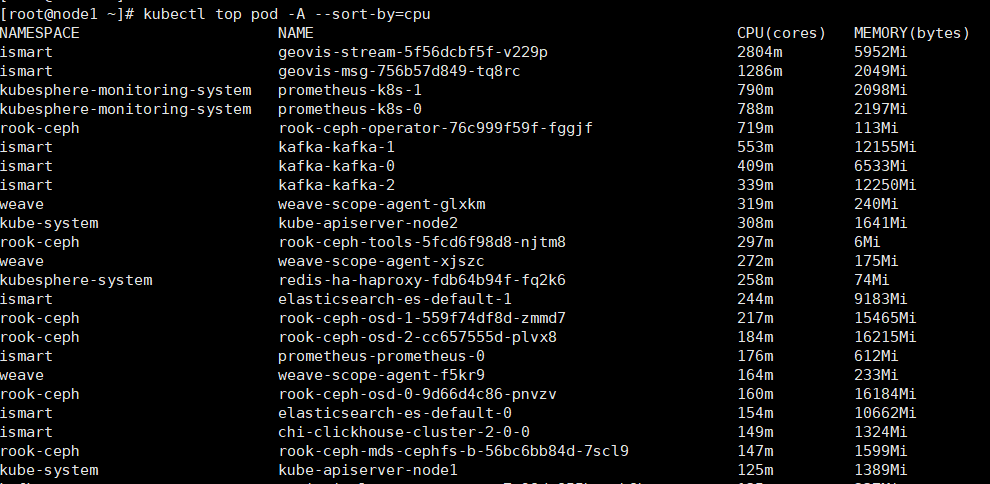
5、Kubernetes pod 内存和CPU占用
1 | |